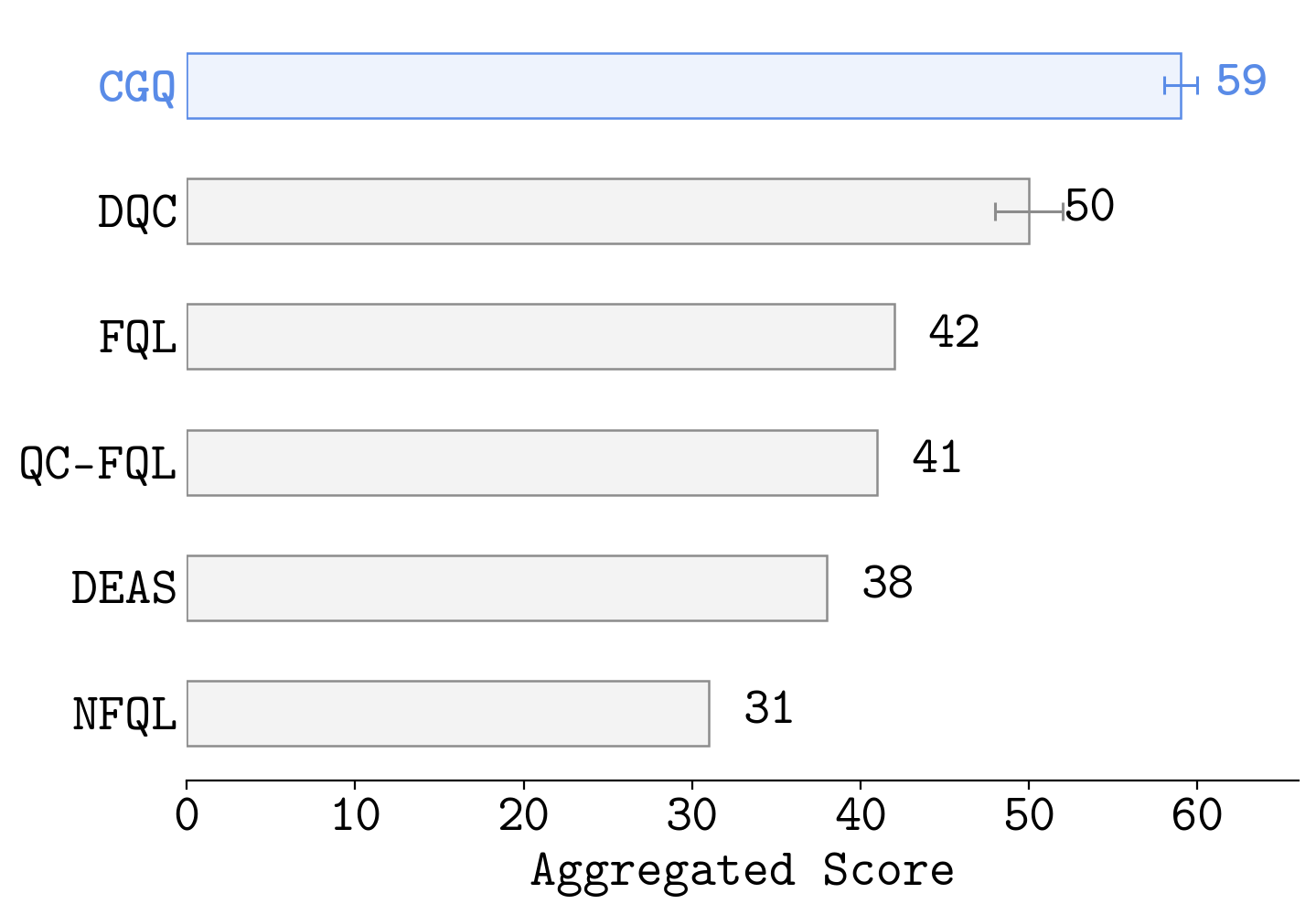
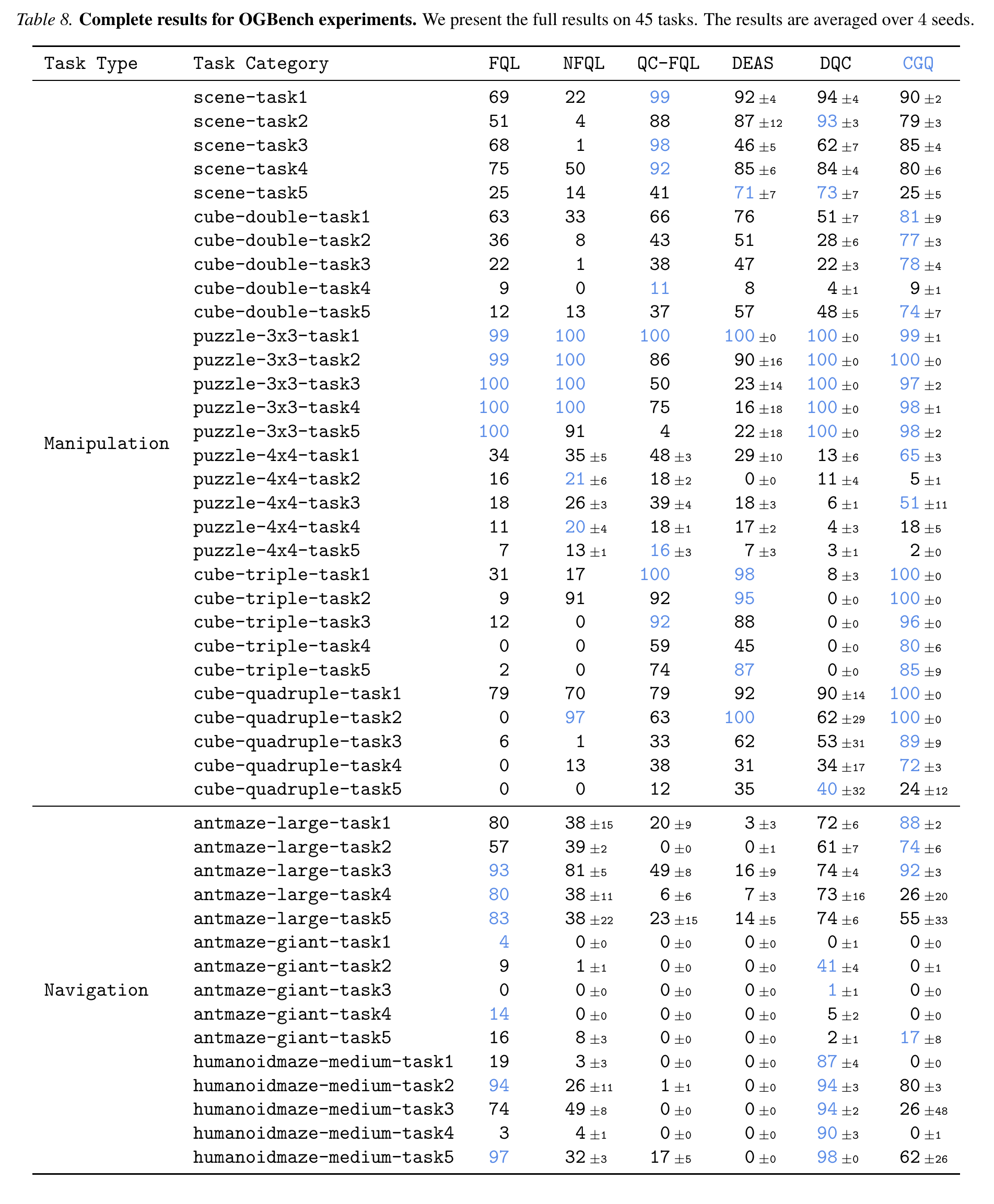
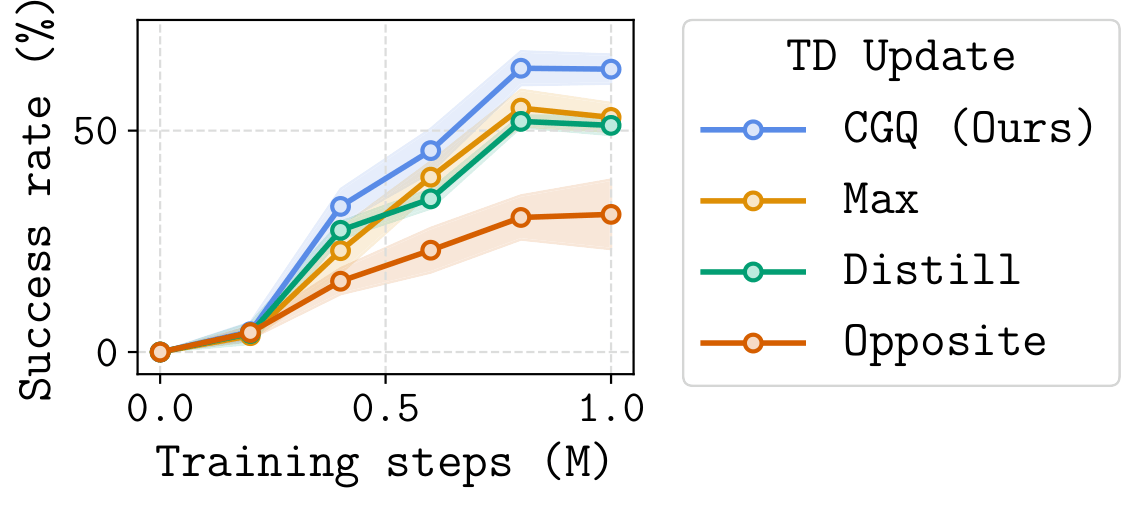
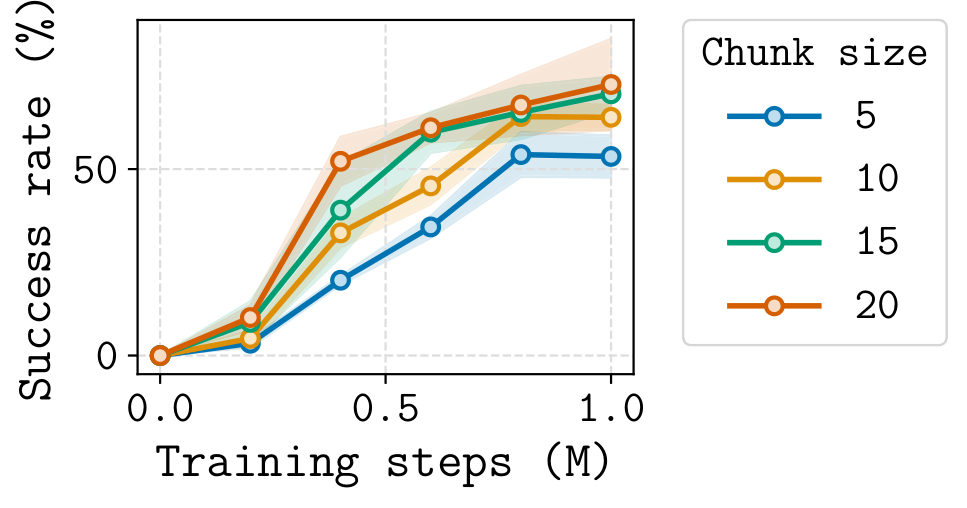
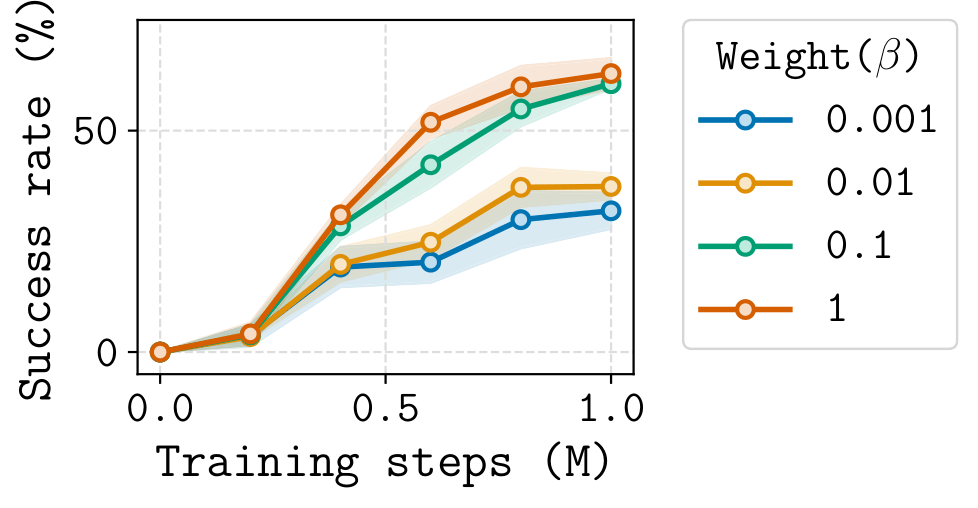
- Chunk-Guided Q-Learning (CGQ) is an offline RL method that trains a reactive single-step policy while leveraging action chunking to stabilize value learning over long horizons.
- CGQ is stable and performant. The chunk-based critic provides a longer-range bootstrap target, reducing compounding error. The single-step critic preserves full reactivity, recovering fine-grained trajectory stitching that chunked methods cannot.
Challenges
Single-step RL
Bootstrapping Error Accumulation
Each Bellman backup bootstraps from the critic's own estimates. Small errors compound across hundreds of steps, overwhelming the learning signal on long-horizon tasks. This problem worsens as the discount factor \(\gamma \to 1\), which is typical in long-horizon settings.
Action-Chunked RL
Suboptimal Value Learning
Chunked TD assumes the policy executes a fixed action sequence without reacting to intermediate states. This restricts the policy class to open-loop sequences, making the value function structurally suboptimal: \(Q^*_{\text{chunk}} \leq Q^*\) in general.
Visualized in a Gridworld
To isolate these problems without confounding factors like function approximation, we study all three approaches in a controlled 18×18 gridworld environment. The agent must navigate from a start position to a fixed goal.
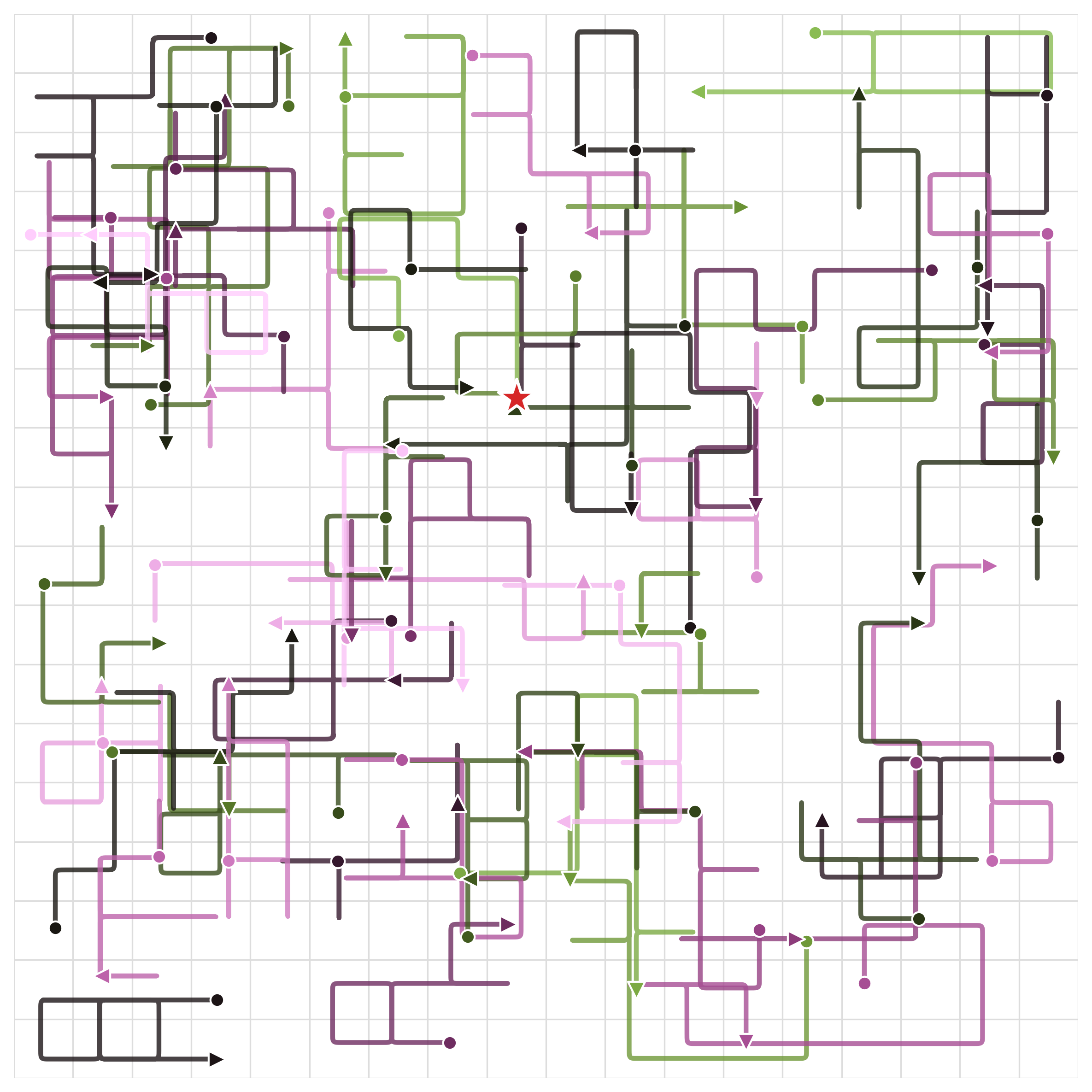
Dataset: 60 trajectories from an ε-greedy policy (ε=0.9)
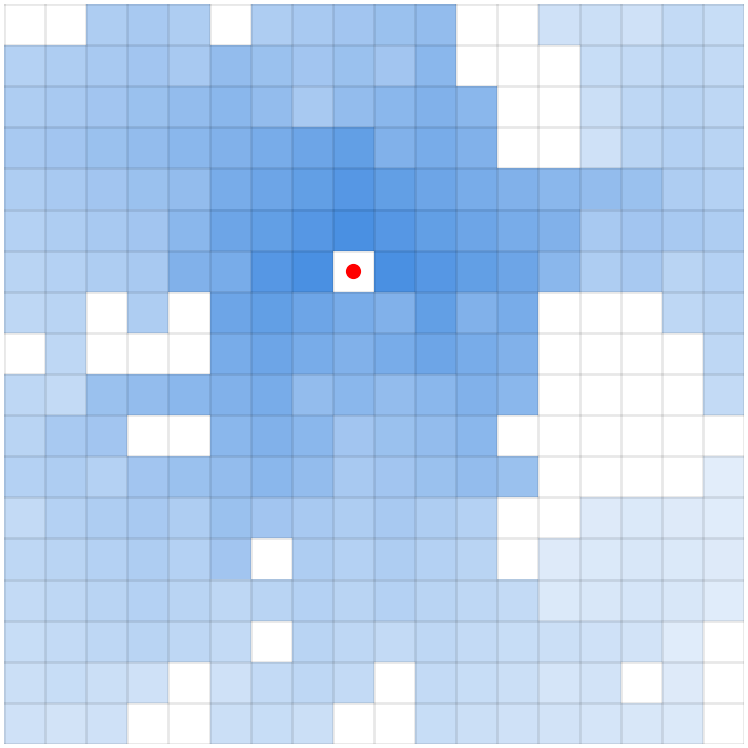
Ground-truth optimal value function V*
The dataset covers diverse paths but is far from optimal, a realistic offline RL setting. We add Gaussian noise (σ=0.05) to each value update to simulate the effect of function approximation error. We then compare how each method's estimated value function evolves over training iterations.
Learned Value Function Over Iterations
Compare each method's learned V(s) against the ground-truth V*. Colors closer to V* = better. Darker-than-V* regions indicate value overestimation.
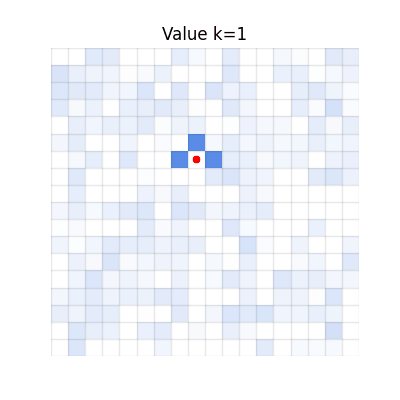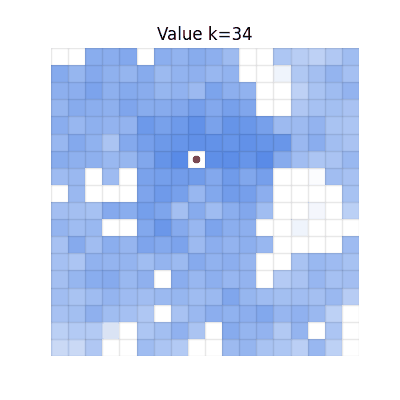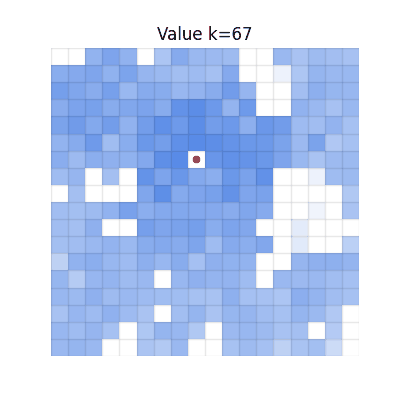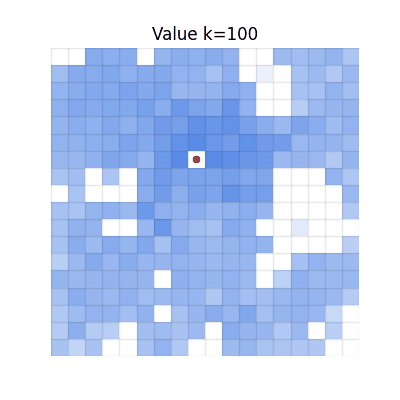
Single-step TD
Values spread, but many regions become darker than V* due to accumulated overestimation from repeated
bootstrapping.
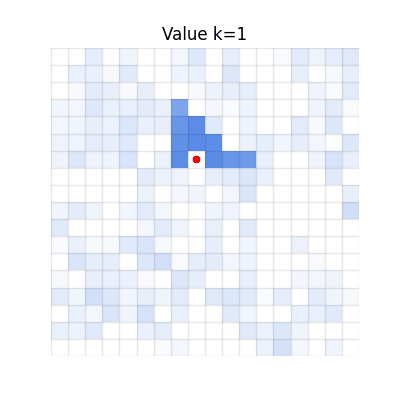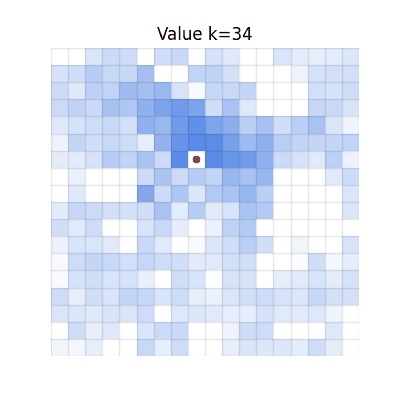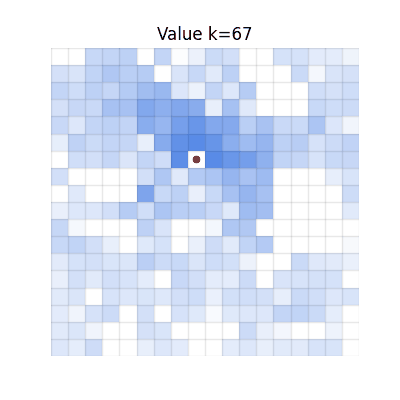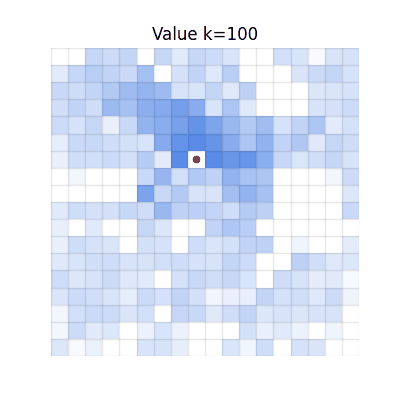
Chunked TD (h=4)
Fast early spread, but plateaus. Even states close to the goal fail to reach the correct value due
to open-loop constraints.
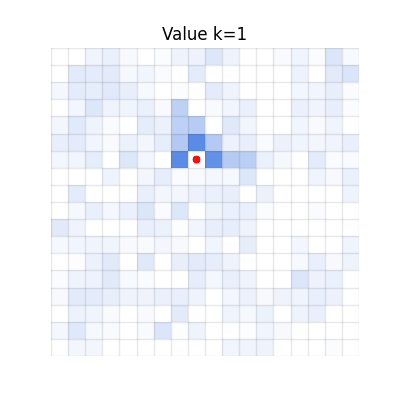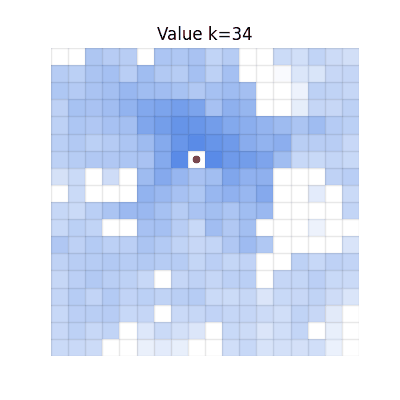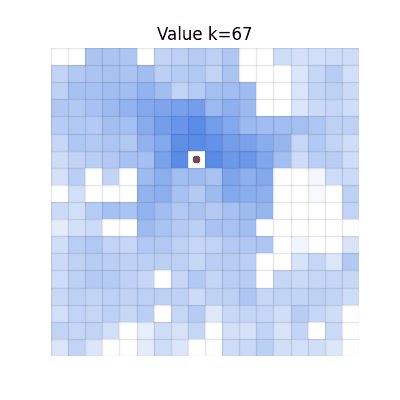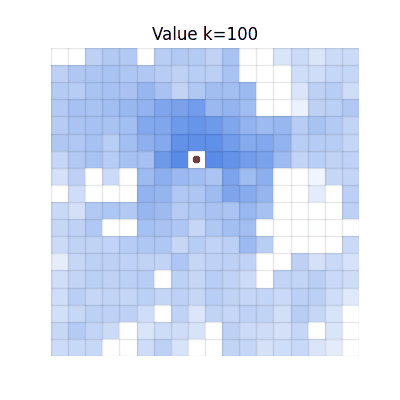
CGQ (Ours)
Converges to match V*. Fast propagation from chunking, correct final values from single-step reactivity.
Value Estimation Error Over Iterations
The animations below show the MSE between each method's value function and V* at every iteration. Brighter regions = larger error.
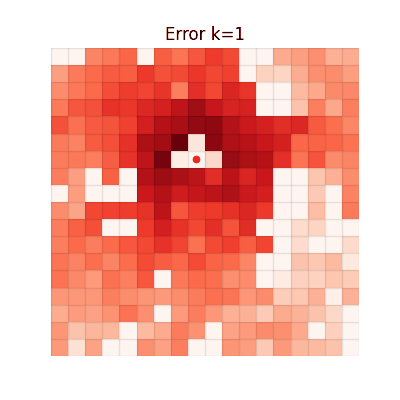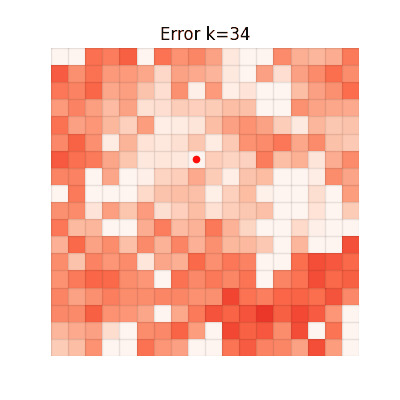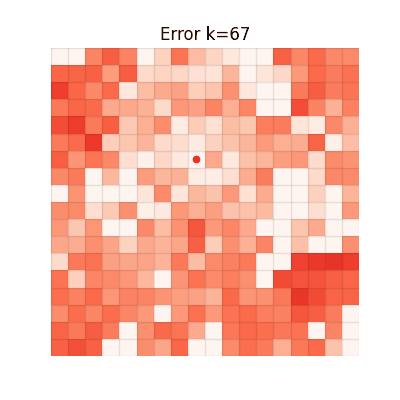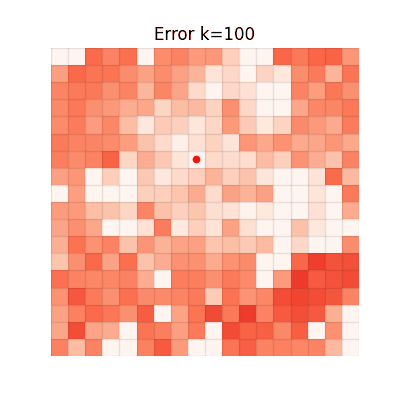
Single-step TD
Error grows with distance from the goal. Farther states require more bootstrapping steps, accumulating
larger estimation errors.
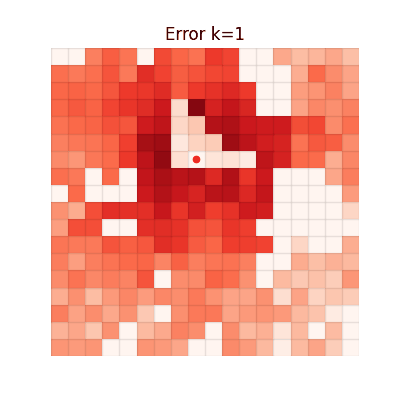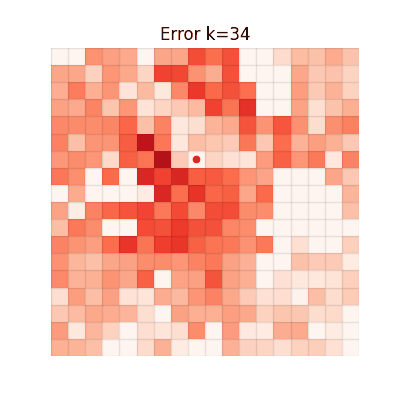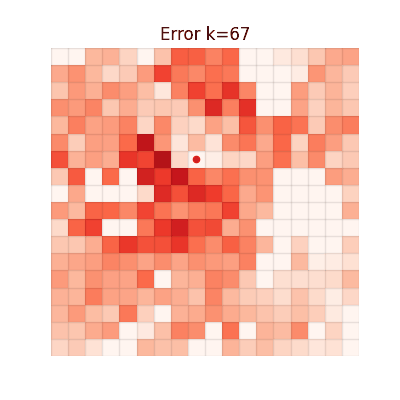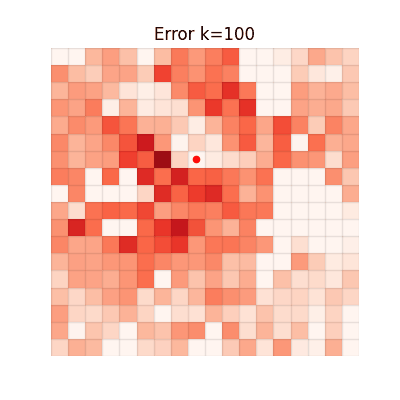
Chunked TD (h=4)
Error drops fast, but plateaus. The open-loop assumption prevents optimal convergence.
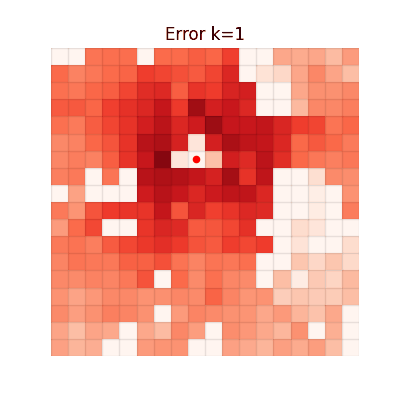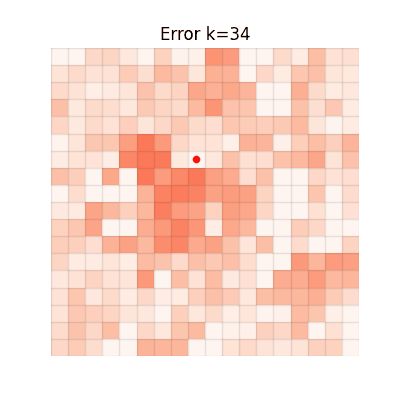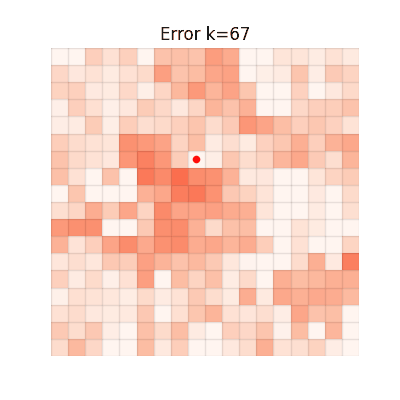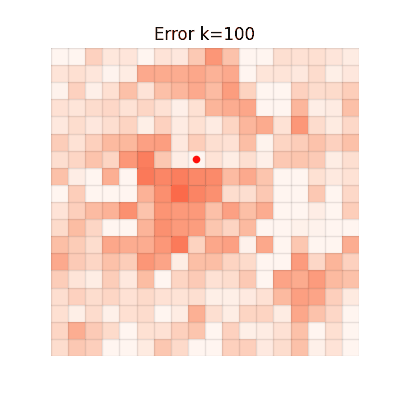
CGQ (Ours)
Fast and accurate, achieving the lowest final error.